
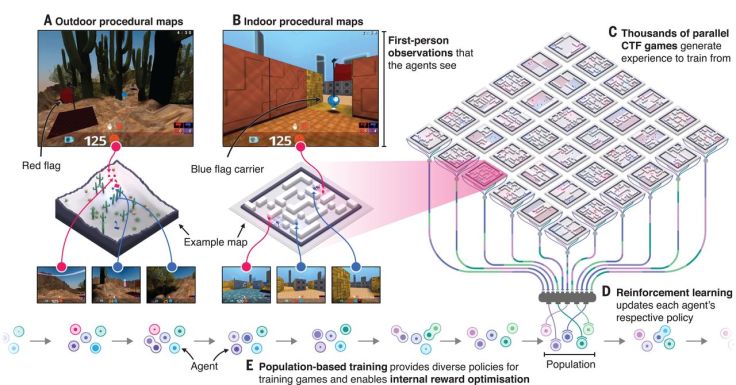
En esta ocasión, los científicos han demostrado el rendimiento de su IA en un entorno poblado por múltiples protagonistas, en el que los agentes han tenido que aprender de forma independiente, pero también cooperar para alcanzar el bien común.
Esto es fundamental, según los investigadores de DeepMind, para que la inteligencia artificial desempeñe tareas cada vez más complejas, sin necesidad de que haya que programar todas y cada una de las posiblidades ante las que se encontrarán.
«Nadie les ha dicho cómo jugar al juego o si han logrado vencer a su enemigo o no», ha dicho Jaderberg. «La belleza de este sistema de aprendizaje por refuerzo es que nunca sabes qué tipos de comportamientos emergerán en los agentes».
Al menos que sepamos, el objetivo de DeepMind no es destruir el mundo, sino desarrollar una inteligencia artificial capaz de lidiar con tareas complejas, como el diseño de medicamentos, materiales y aplicaciones biotecnológicas, para hacerlo un poco mejor. Lo que parece seguro es que el futuro nos traerá cosas que hoy no podemos ni imaginar.



Deja un comentario